Something went wrong on a homelab server and Docker stopped cleaning up old overlays.
Running docker system prune -a -f (via) seemed to fix it.
Total reclaimed space: 149GB :tada:
LM66200 Seems like a good place for me to start
I'm excited to see other folks interested in a Limbo/SQLx integration.
SQLx + support for an S3 store falls close to my ideal use case for application DB usage.
It's nice to see more OIDC services coming out that (presumably) work well for self-hosting. Pocket-ID (via This Week in Self-Hosted and Rauthy.
I'm still using kanidm with no need to switch, but it's nice to see maybe-easier things to recommend for other folks to try!
TIL about MTP Cable.
I've wanted to run some fiber to connect into my office. Right now it's 10G over copper, it would be nice to run something that takes less power than 10GBe though.
I used the duty cycle of my existing furnace to calculate the size of a replacement heat pump. The HVAC contractor salesperson at Gen3 didn't seem to use that information though. I thought the modulation of the Mitsubishi system would still be ok, but it wasn't. The minimum BTUs for the new system are still high enough that the system doesn't modulate.
Based on the energy usage and efficiency of the new system, the previous duty calculations seemed to be accurate for the heating load! It's nice to see this method discussed.
I have a Sense Energy Monitor but would really like a local solution, ideally Z-Wave as a bunch of my house is already Z-wave-d. Aeotec makes a whole house energy monitor but I need more clamps to monitor things like my HVAC system which can't be tracked with smart plugs.
The Sense learning for appliances hasn't worked all that well with variable loads and it seems to have trouble discerning between the various heat pumps in the house.
IoTaWatt was previously out of stock for a while. It's wifi, but can accommodate more clamps.
HVAC Journey: Mitsubishi Equivalent Pipe Length
Posted onWhile trying to debug problems with my HVAC system I came across "equivalent pipe length". Mitsubishi seems to omit this from installation manuals but includes it in their engineering manuals.
Equivalent Pipe Length accounts for the pressure drop of fittings, valves, or bends in a line to help simplify limits for a system. If a system has a max line length of 100' the measured distance of 100' would assume no additional parts in line to drop the pressure. If you add fittings, valves, or bends then the measured length would need to be below 100' to stay within the system limits specified as equivalent pipe length.
An example
As a practical example. Here is my system (as best I could model in Diamond System Builder):
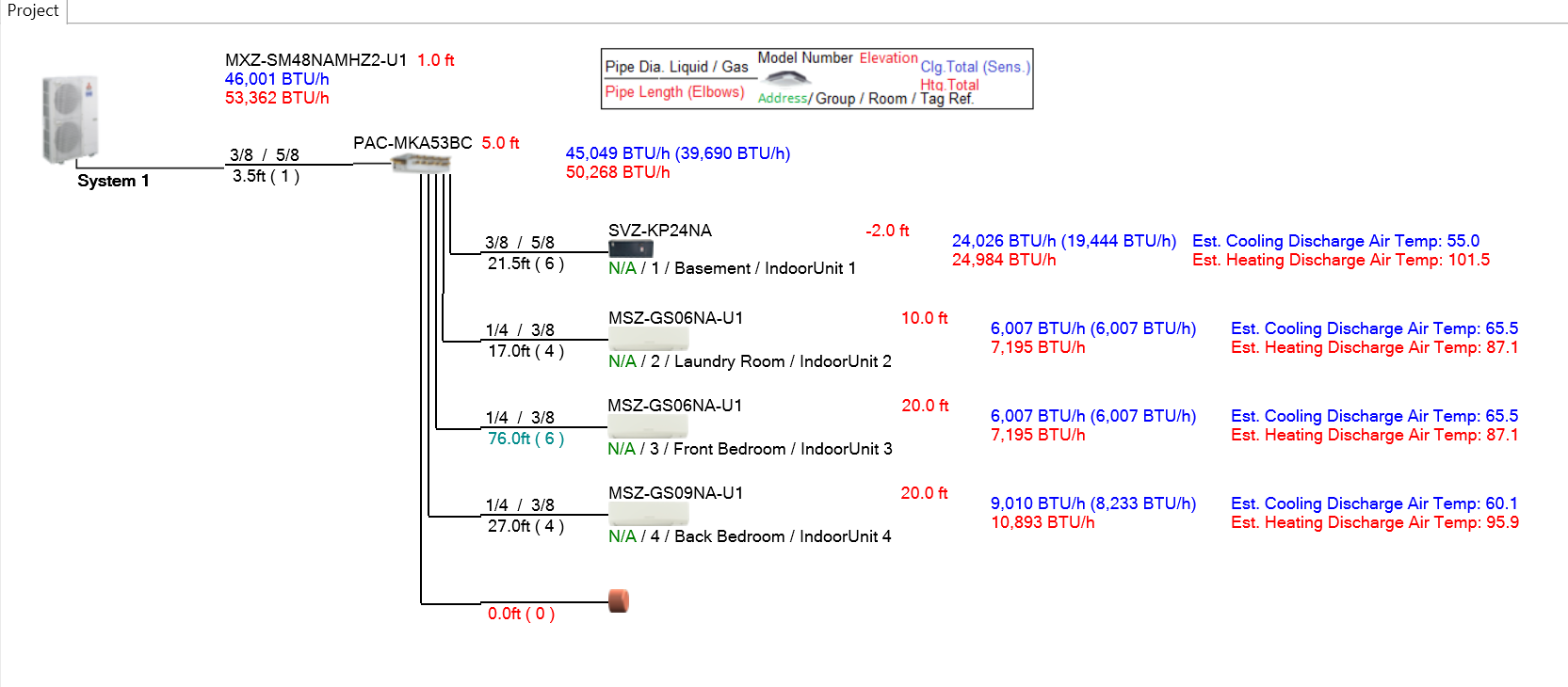
I have a single outdoor unit with 4 indoor units: a central air handler and 3 mini splits. The lengths listed in this diagram are the measured lengths. The system will calculate the equivalent pipe length automatically and check it against the equipment specifications listed, pretty cool.
I cannot however correctly model my system in Diamond System Builder though as the measured length for the Front Bedroom is 84', with 6 bends.
For my outdoor unit. The installation manual states the Farthest piping length after Branch box of 82'. The 82' is the equivalent pipe length NOT the measured pipe length.

I've confirmed with a Mitsubishi representative that the installation manual uses the equivalent pipe length, not the measured pipe length. This aligns with the System Builder where I can input 82' if I use 0 bends. The max length I can use with the 6 real-world bends in my system is 76'.
In the engineering manual there is a calculation for the equivalent pipe length on this system:

Which is why I can only input 76' feet with 6 bends (76' + 6 * 0.99' = 81.94').
How would someone know
I'm not sure how someone would know the installation manual uses equivalent pipe length. Maybe this is covered in training for Mitsubishi equipment. My Mitsubishi Diamond Elite contractors seem not to know about it though. Or at least this didn't seem to stop them from installing this equipment in what appears to me to be out of spec from the manufacturer.
The scale of hyperscaler datacenters and this cut back are difficult to comprehend. I guess with these cuts there still isn't a general-public killer-app for AI yet, or even planned.
I've on and off again spent time trying to find some replacement for Postgres for software I write. Postgres is wonderful but is also a heavy requirement for lots of little homelab services. I tend to run a Postgres instance for each service which takes quite a bit of memory and maintenance overhead.
In Rust-land there is DataFusion that has a SQL interface for querying and inserting data. Inserting data can be a bit messy though and seems very much not to be the focus.
DataFusion is integrated well with Delta though! Delta appears really interesting! It can use memory, filesystem, or remote storage. It supports write fairly well, including (fairly manually) the maintenance items that folks complain about with Postgres (compaction/vacuuming).
It took a day but I have a working prototype of creating a table on Minio, inserting data, and querying the table. Examples on Delta's site seem out of date and overly verbose at the same time.
I ran into a problem with my homelab Minio cluster where a single node was able to corrupt the ls of a bucket. With that node turned off ls showed the latest files, with the node running ls wouldn't list any files added in the last month. Writes were fine in either case, other than not being ls-able. A manual heal on the cluster seemed to fix it fine enough.